HDFS小文件处理解决方案总结+facebook(HayStack) + 淘宝(TFS)
http://www.open-open.com/lib/view/1330605869374
一、概述
手机图片或者像淘宝这样的网站中的产品图片特点:
(1)、大量手机用户同时在线,执行上传、下载、read等图片操作
(2)、文件数量较大,大小一般为几K到几十K左右
HDFS存储特点:
(1) 流式读取方式,主要是针对一次写入,多次读出的使用模式。写入的过程使用的是append的方式。
(2) 设计目的是为了存储超大文件,主要是针对几百MB,GB,甚至TB的文件
(3) 该分布式系统构建在普通PC机组成的集群上,大大降低了构建成本,并屏蔽了系统故障,使得用户可以专注于自身的操作运算。
HDFS与小图片存储的共通点和相悖之处:
(1) 都建立在分布式存储的基本理念之上
(2) 均要降低成本,利用普通的PC机构建系统集群
(1) HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放1million的文件至少消耗300MB内存,如果要存 放1billion的文件数目的话会超出硬件能力
(2) HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入1million的files,那么HDFS 将花费几个小时的时间。
(3) 流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
二、HDFS文件操作流程

reading:

writing:

三、HDFS自带的小文件存储解决方案
对于小文件问题,hadoop自身提供了三种解决方案:Hadoop Archive、 Sequence File 和 CombineFileInputFormat
(1) Hadoop Archive

归档为bar.har文件,该文件的内部结构为:

创建存档文件的问题:
1、存档文件的源文件目录以及源文件都不会自动删除需要手动删除
2、存档的过程实际是一个mapreduce过程,所以需要需要hadoop的mapreduce的支持
3、存档文件本身不支持压缩
4、存档文件一旦创建便不可修改,要想从中删除或者增加文件,必须重新建立存档文件
5、创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
(2) Sequence File
sequence file由一系列的二进制的对组成,其中key为小文件的名字,value的file content。

创建sequence file的过程可以使用mapreduce工作方式完成
对于index,需要改进查找算法
对小文件的存取都比较自由,也不限制用户和文件的多少,但是该方法不能使用append方法,所以适合一次性写入大量小文件的场景
(3) CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
该方案版本比较老,网上资料甚少,从资料来看应该没有第二种方案好。
四、WebGIS解决方案概述
在地理信息系统中,为了方便传输通常将数据切分为KB大小的文件存储在分布式文件系统中,论文结合WebGIS数据的相关特征,将相邻地理位置的小 文件合并成一个大的文件,并为这些文件构建索引。论文中将小于16MB的文件当做小文件进行合并处理,将其合并成64MB的block并构建索引。

从以上索引结构和文件存储方式可以看出,index是一般的定长hash索引,并且采用的是存储全局index文件的方式
read的过程是将小文件append到下文件后边,然后更新索引的过程
delete文件的过程采用lazy模式,更改的是FVFlag,在空间重新分配的过程中,才会根据该flag删除文件。
五、BlueSky解决方案概述
BlueSky是中国电子教学共享系统,主要存放的教学所用的ppt文件和视频文件,存放的载体为HDFS分布式存储系统。在用户上传PPT文件的 同时,系统还会存储一些文件的快照,作为用户请求ppt时可以先看到这些快照,以决定是否继续浏览,用户对文件的请求具有很强的关联性,当用户浏览ppt 时,其他相关的ppt和文件也会在短时间内被访问,因而文件的访问具有相关性和本地性。
paper主要提出了两个基本观点:
(1) 将属于同一课件的小文件合并成一个大文件,从而减轻namenode的压力,提高小文件的存储效率
(2) 提出了一种两级预取机制以提高小文件的读取效率,(索引文件预取和数据文件预取)索引文件预取是指当用户访问某个文件时,该文件 所在的block对应的索引文件被加载到内存中,这样,用户访问这些文件时不必再与namenode交互了。数据文件预取是指用户访问某个文件时,将该文 件所在课件中的所有文件加载到内存中,这样,如果用户继续访问其他文件,速度会明显提高。
BlueSky上传文件的过程:

BlueSky阅览文件的过程:

文件合并:
文件合并过程如果合并之后文件的大小小于block64MB的大小则直接存放到一个block中。(合并之后的文件包括local index文件)
如果合并之后的文件大小大于64MB有两种方式split这个大文件:
1、 local index文件、ppt文件、standresolution picture series存放在一个block中,剩下的picture series存在在其他的block中。
2、 在相邻block的连接处填充空白文件,具体过程:

文件映射:
文件的命名方式,分离的预取图片有其自身的命名方式,具体见paper。文件映射过程中,除了block中的局部索引文件之外,还有一个全局映像文 件。该文件存放的内容为
根据全局mapping table 就可以根据merged file name 和 block Id到namenode上得到datanode的信息,然后到根据到具体的机器上找到相应的block获取到localindex file,根据original file name从local index file中查到从而定位到data。根据预取策略,在此过程中也会预取到local index file 和相关的file
六、facebookHayStack解决方案概述


haystack是一个不同于HDFS的分布式系统,如果想在HDFS的基础上构建小文件存储系统,个人认为可以参考借鉴其索引结构的设计。
1、 directory 中有logical volume id<->physicalvolume id。根据可以通过directory拼出来http:////id>/ 。 因此在directory端存在着映射以及映射
2、 根据url到store端之后,可以根据logicalvolume id获得相应的physical volume的位置,然后physical中存在super block,根据映射可以得到photo数据
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。

TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文 件。!DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部 load在内存,除非出现!DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。
TFS中之所以可以使用namenode存放元数据信息的一个原因在于不像HDFS的元数据需要存放,filename与block id的映射以及block id与datanode的映射。在TFS中没有file的概念,只有block 的映射信息。所有的小文件被拼接成block。所以namenode中只需要存放的映射以及的映射。这样一来元数据信息就会减少很多,从而解决HDFS的namenode的瓶颈问题。
在TFS中,将大量的小文件(实际用户文件)合并成为一个大文件,这个大文件称为块(Block)。TFS以Block的方式组织文件的存储。每一 个Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。 在!NameServer节点中存储了所有的Block的信息,一个Block存储于多个!DataServer中以保证数据的冗余。对于数据读写请求, 均先由!NameServer选择合适的!DataServer节点返回给客户端,再在对应的!DataServer节点上进行数据操 作。!NameServer需要维护Block信息列表,以及Block与!DataServer之间的映射关系,其存储的元数据结构如下:

八、一种提高云存储小文件效率的解决方案
(美国西北太平洋国家实验室2007年的一份研究报告表明,他们系统中有1 200万个文件,其中94%的文件小于64 MB,58%的小于64 kB。在一些具体的科研计算环境中,也存在大量的小文件,例如,在某些生物学计算中可能会产生3 000万个文件,而其平均大小只有190 kB。)

系统为每个用户建立了3种队列:
序列文件队列(SequenceFile queue,SFQ),
序列文件操作队列(SequenceFile operation queue,SFOQ),
备用队列(Backup queue,BQ)。
其中,SFQ用于小文件的合并,SFOQ用于对合并后小文件的操作,BQ用于操作的小文件数超过SFQ或SFOQ长度的情况。

Hadoop小文件问题
http://www.gfzj.us/series/small-files/2015/01/06/hadoop-small-file.html
海量小文件对于Hadoop来说是一个灾难。如果不可避免的要使用Hadoop处理小文件,此处提供一些方案。
Problems with small files and HDFS
小文件是指那些文件大小比HDFS block size(默认64M)小很多的文件。每个小文件即使size很小,仍旧会占用一个block,不会多个小文件共用一个block。如果你在使用Hadoop时需要存储小文件,那么就意味着你可能有很多小文件,否则不会选择使用Hadoop。但是,问题就在于HDFS不能处理大量的文件。
HDFS中每一个文件、目录或是block在namenode的内存中都对应一个对象,每个对象占用150个字节,因此,一千万个小文件,每个占用一个block,那么namenode就要消耗大约2G的内存。如果有更多的小文件,意味着namenode需要消耗更多的内存,而现有的计算机硬件可能会难以满足相应需求,且会导致集群难以扩展。
另外,HDFS并不是为了有效地访问小文件而设计的:其初衷是为了流式访问大文件。如果访问大量小文件,需要执行大量的seeks操作,并需要不断地从一个datanode跳到另一个datanode,从而获取每个小文件,然而,上述每个操作都是低效的数据访问方式。
Problems with small files and MapReduce
Map tasks通常是以block为单位进行数据的处理。如果文件非常小且文件数量极大,那么每个map task处理的数据就非常少,且需要启动大量的map tasks,而记录每个map task信息(bookkeeping)也需要一定的开销。举个例子:一个是单独的1GB的文件,在HDFS中存储到16个64MB blocks;另一个是10000个100KB的小文件,大约共1GB。这10000个文件每个都用一个map task处理,那么处理这些文件所需的时间要比第一种情况慢上十倍甚至百倍。
Hadoop提供了一些方法用于减少bookkeeping带来的开销:设置mapred.job.reuse.jvm.num.tasks属性,允许一个JVM同时执行多个map tasks,以这种重用task JVM的方式减少启动多个JVM的开销;使用MultiFileInputSplit,每个map task可处理多个blocks数据。
PS: bookkeeping是指在一个job的初始化阶段记录每个task的状态和进度。
One Example
一个非常典型的小文件案例就是存储海量图片,每个图片是一个单独的小文件,这种情况就需要使用一个容器把图片进行分组打包存储。
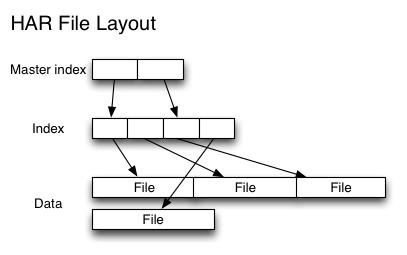
HAR files
为了缓解大量小文件带给namenode内存的压力,Hadoop 0.18.0引入了Hadoop Archives(HAR files),其本质就是在HDFS之上构建一个分层文件系统。通过执行
hadoop archive命令就可以创建一个HAR文件。在命令行下,用户可使用一个以har://开头的URL就可以访问HAR文件中的小文件。使用HAR files可以减少HDFS中的文件数量。
下图为HAR文件的文件结构,可以看出来访问一个指定的小文件需要访问两层索引文件才能获取小文件在HAR文件中的存储位置,因此,访问一个HAR文件的效率可能会比直接访问HDFS文件要低。对于一个MapReduce任务来说,如果使用HAR文件作为其输入,仍旧是其中每个小文件对应一个Map task,效率低下。所以,HAR files最好是用于文件归档。

Sequence Files
除了HAR files,另一种可选是SequenceFile,其核心是以文件名为key、文件内容为value组织小文件。回到之前提到的10000个100KB大小的文件,你可以编写程序将这些文件放到一个SequenceFile文件,然后就以数据流的方式处理这些文件,也可以使用MapReduce进行处理。一个SequenceFile是可分割的,所以MapReduce可将文件切分成块,每一块独立操作。不像HARs,SequenceFile支持压缩。在大多数情况下,以block为单位进行压缩是最好的选择,因为一个block包含多条记录,压缩作用在block之上,比Record压缩方式(一条一条记录进行压缩)的压缩比高。
把已有的数据转存为SequenceFile比较慢。比起先写小文件,再将小文件写入SequenceFile,一个更好的选择是直接将数据写入一个SequenceFile文件,省去小文件作为中间媒介。
下图为SequenceFile的文件结构。HAR files可以列出所有keys,但是SequenceFile是做不到的,因此,在访问时,只能从文件头顺序访问。

HBase
HBase也可用于存储小文件,前提是文件真的很小。
个人总结
对于海量小文件,该如何处理:
- 如果文件大小能保证在一个较小的范围内,使用HBase
- 如果小文件的大小不能保证,考虑将文件直接写入HDFS,并在HBase中存储其实际地址
- 如果小文件是每天都产生,那么可以考虑使用HAR files或者SequenceFile(或基于其的方式,如MapFile),并将源文件删除,在HBase中存储实际地址。
如果用户需要通过HBase中的地址访问存储在HDFS中的小文件,那么就需要写相关服务来提供该功能了。
http://blog.chinaunix.net/uid-20577907-id-3989644.html
一、概述
首先明确概念,这里的小文件是指小于HDFS系统Block大小的文件(默认64M),如果使用HDFS存储大量的小文件,将会是一场灾难,这取决于HDFS的实现机制和框架结构,每一个存储在HDFS中的文件、目录和块映射为一个对象存储在NameNode服务器内存中,通常占用150个字节。如果有1千万个文件,就需要消耗大约3G的内存空间。如果是10亿个文件呢,简直不可想象。这里需要特别说明的是,每一个小于Block大小的文件,存储是实际占用的存储空间仍然是实际的文件大小,而不是整个block大小。
为解决小文件的存储Hadoop自身提供了两种机制来解决相关的问题,包括HAR和SequeueFile,这两种方式在某些方面解决了本层面的问题,单仍然存在着各自的不足。下文讲详细说明。
二、Hadoop HAR
Hadoop Archives (HAR files) ,这个特性从Hadoop 0.18.0版本就已经引入了,他可以将众多小文件打包成一个大文件进行存储,并且打包后原来的文件仍然可以通过Map-reduce进行操作,打包后的文件由索引和存储两大部分组成,索引部分记录了原有的目录结构和文件状态。其原理如下图所示:
缺点:
- HAR 方式虽然能够实现NameNode内存空间的优化,但是他是一个人工干预的过程,同时他既不能够支持自动删除原小文件,也不支持追加操作,当有新文件进来以后,需要重新打包。
- HAR files一旦创建就不能修改,要做增加和修改文件必须重新打包。事实上,这对那些写后便不能改的文件来说不是问题,因为它们可以定期成批归档,比如每日或每周。
- HAR files目前还不支持文档压缩。
三、SequeuesFile
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0版本开始中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩、文件级、块级别)。其存储结构如下图所示:

示例代码如下所示:
private static void writeTest(FileSystem fs, int count, int seed, Path file,
CompressionType compressionType, CompressionCodec codec)
throws IOException {
fs.delete(file, true);
LOG.info("creating " + count + " records with " + compressionType +
" compression");
CompressionType compressionType, CompressionCodec codec)
throws IOException {
fs.delete(file, true);
LOG.info("creating " + count + " records with " + compressionType +
" compression");
//指明压缩方式
SequenceFile.Writer writer =
SequenceFile.createWriter(fs, conf, file,
RandomDatum.class, RandomDatum.class, compressionType, codec);
RandomDatum.Generator generator = new RandomDatum.Generator(seed);
for (int i = 0; i < count; i++) {
generator.next();
SequenceFile.Writer writer =
SequenceFile.createWriter(fs, conf, file,
RandomDatum.class, RandomDatum.class, compressionType, codec);
RandomDatum.Generator generator = new RandomDatum.Generator(seed);
for (int i = 0; i < count; i++) {
generator.next();
//keyh
RandomDatum key = generator.getKey();
RandomDatum key = generator.getKey();
//value
RandomDatum value = generator.getValue();
//追加写入
writer.append(key, value);
}
writer.close();
}
RandomDatum value = generator.getValue();
//追加写入
writer.append(key, value);
}
writer.close();
}
缺点:
目前为止只发现其Java版本API支持,未在其他开发接口中发现相关版本的实现,尤其是LibHDFS和thrift接口中,可能真是C++阵营狂热支持者的一个悲剧。
四、Hbase
如果你需要处理大量的小文件,并且依赖于特定的访问模式,可以采用其他的方式,比如Hbase。Hbase以MapFiles存储文件,并支持Map/Reduce格式流数据分析。对于大量小文件的处理,也不失为一种好的选择。
Hadoop关于处理大量小文件的问题和解决方法
http://os.51cto.com/art/201310/413719.htm
小文件指的是那些size比HDFS的block size(默认64M)小的多的文件。如果在HDFS中存储小文件,那么在HDFS中肯定会含有许许多多这样的小文件(不然就不会用hadoop了)。而HDFS的问题在于无法很有效的处理大量小文件。

沒有留言:
張貼留言